






Inaccurate AI outputs don't always look off. That's what makes them dangerous.
The numbers are pulled correctly, the response is formatted cleanly, and the confidence in the tone gives you no reason to question them. But somewhere in the logic, a metric was calculated wrong, a relationship between data points was missed, or an operational change wasn't accounted for. And you don’t want to be in the position of catching these mis-steps after the fact.
The gap between tools isn’t the AI model. What separates them is trusted context: a grounded, specific understanding of how your commerce business actually works. That’s what Triple Whale built the Context Engine to provide, and it’s something that can’t be vibe-coded or cloned.
In a world where most platforms are shipping an AI layer, the product difference comes down to how well they comprehend the business behind the data. With data collected from over 60K brands daily, we know it inside and out.
There's a version of AI-powered analytics that's become pretty standard: connect a language model to your data, let it generate responses, call it intelligent. It works well enough when the questions are simple. It falls apart when the questions are nuanced and business growth depends on the outputs.
The reason isn't that the underlying models are bad. It's that intelligence without context produces confident-sounding guesses. And in ecommerce, a confident-sounding guess dressed up as analysis can do real damage. You scale a campaign that was already fatiguing. You pull budget from a channel that was actually working. You forecast inventory on projections that had no business context behind them.
Generic AI tools have access to your numbers. What they're missing is everything that makes those numbers mean something.
The Context Engine is the intelligence trust layer that sits beneath Moby, Triple Whale's AI.
It's a set of interconnected capabilities that together give Moby genuine fluency in how your business operates: how your data is defined, how your metrics relate to each other, what good looks like for brands like yours, what your team has actually done across your ad accounts, and what experienced operators do when faced with the same situation you're in.
Together, they make Moby's outputs trustworthy in a way that general-purpose AI tools simply cannot replicate.
Moby connects directly to your live business data and queries it in real time. No exports, no uploads, no separate data feeds to maintain. When you ask a question, Moby is looking at what's actually happening right now — across all of your primary data sources — ready to query at a moment's notice.
Most operators using generic AI tools don't have this luxury. They're downloading data from their platforms, uploading it to an LLM, and working with something that's already outdated the moment it leaves the source. Some are going further — using browser-based tools to scrape data in real time — but that approach is slow, brittle, and prone to pulling inaccurate numbers. Either way, the data pipeline itself becomes a liability before any analysis even begins.
In an industry like ecommerce that moves fast, you can’t afford that delay. That’s why Moby can also run on a schedule to check any connected dataset as often as every 30 minutes, meaning the decisions you're making are grounded in what's actually happening, not a snapshot from whenever you last ran a download.
This matters even more when you factor in advertising data. Triple Whale goes beyond just connecting to your store data — we have accurate, first-party measurement for your advertising performance across platforms. That's a fundamental advantage over simply feeding platform exports into Claude or ChatGPT. Plus, ad platforms themselves report differently, use different attribution windows, and define metrics inconsistently. So, the data getting uploaded can have a schema mismatch and a generic LLM working from a raw export has no way of knowing that. Moby does.
Underneath all of this is a structured data retrieval system that Triple Whale has spent over three years building and refining. With the latest version of Moby, text-to-SQL accuracy has improved by over 40% - from a 0.61 SQL score to 0.85 driven by a fully agentic retrieval architecture.
That jump came from two things working together. First, a fundamental redesign of the retrieval system, moving from a predefined, multi-step data workflow to an agentic architecture where Moby reasons through each query dynamically: adaptive knowledge base lookups mid-reasoning, parallel query execution, and self-correction logic that catches edge cases before they become bad outputs.
Second, a new generation of frontier models. Moby gives users access to state-of-the-art models from all three leading labs — including GPT 5.4, Claude 4.6 Opus, and Gemini 3.1 Pro — out of the box. The agentic architecture performs well with any model, but the visible leap in accuracy and intelligence came when these two pieces clicked together.
The result is an AI that answers harder questions correctly. The kind of questions that involve multiple data sources, complex time windows, and metrics that need to be calculated rather than simply looked up. And Moby learns from every interaction: the more your team uses it, the sharper it gets.
The accuracy comes from Triple Whale's semantic layer: a data dictionary and ontology that defines every metric, every calculation, and every relationship between data points with precision.
Why is this important? Ecommerce metrics don't exist in isolation. Your new customer acquisition cost connects to your LTV, which connects to your payback period, which connects to how aggressively you should bid on top-of-funnel keywords. A ROAS number means something very different for a brand with high repeat purchase rates than for one that's almost entirely new customer dependent.
Generic AI tools know what ROAS stands for. They don't understand how it should inform decisions given your specific business model and margin structure.
Moby does, because Triple Whale has built a domain knowledge layer that maps how ecommerce metrics relate to each other and what they mean in different business contexts.
You're getting output from something that reasons about ecommerce the way an experienced operator would, not something that pattern-matches against common business content from the web.
One of the more quietly powerful parts of the Context Engine is the commerce-playbook component. We worked with real ecommerce marketing experts to build analysis frameworks and diagnostic workflows that Moby applies automatically across all accounts.
In practice, this means when you ask Moby why your CPA spiked, it doesn't just pull the number and describe the change. It walks through the same diagnostic an experienced media buyer would run: checking spend allocation across channels, looking for creative fatigue signals, comparing performance across audience segments, surfacing anomalies in your bid strategy. You're getting analyst-grade thinking baked into the default behavior.
For operators who are newer to this level of analytical rigor, the playbooks provide a structured starting point. For operators who are already sophisticated, they accelerate analysis significantly. Either way, you're not building from a blank slate.
And the playbook library isn't static. If your team has developed its own way of diagnosing performance or evaluating creative, you can teach it to Moby directly. Just walk Moby through your process (playbook) in a conversation and tell it to remember. From that point forward, Moby applies your playbook the same way it applies the expert-built ones. The result is an AI that gets smarter about how your specific team thinks, on top of everything it already knows about ecommerce.
Every metric exists on a spectrum, and knowing where you land on that spectrum changes how you respond to it.
A 20% conversion rate is either a sign of a healthy check-out engine or a warning sign, depending entirely on what comparable brands in your category look like. Moby has access to industry benchmark data and references it automatically when contextualizing your performance.
So when it surfaces a number, it can also tell you whether that number is strong, average, or worth paying attention to. This shifts the analysis from simply being descriptive to directional.
Here's a common frustration: you're looking at a performance drop from three weeks ago and you have no idea what caused it. You know something changed, but you just can't trace it.
Triple Whale automatically records every campaign, ad set, and ad change across all connected platforms, including changes made directly on Meta or Google outside of Triple Whale. Moby has access to this full activity history and uses it to connect performance shifts to specific actions.
So when your CPA spikes on a Thursday, Moby can surface that someone changed your bid strategy on Wednesday. When revenue dips the week after a creative refresh, Moby can link those two events and help you understand the relationship. Most AI tools can describe what happened to your metrics. The action log gives Moby the ability to explain why, which is really the only version of that answer that's actually useful.
Off-the-shelf forecasting models are trained to find patterns in time-series data. Understanding why ecommerce time-series data looks the way it does is a different challenge entirely.
A DTC brand running a sitewide sale creates a revenue spike that a generic model could treat as an anomaly. A brand launching a new hero product creates customer acquisition patterns that look nothing like their historical baseline. Post-holiday revenue normalization follows curves that are specific to how ecommerce businesses behave, not how businesses at large behave.
Triple Whale's forecasting model is trained on aggregated data from thousands of ecommerce stores. It's seen these patterns play out at scale, across categories, business models, and growth stages.
When Moby produces a projection, it's drawing on that library of real ecommerce behavior, instead of producing a statistical curve that’s fitted to your own historical data in isolation.
At some point, every operator using AI for business decisions will have to answer a simple question: do I actually trust this output? It's easy to dismiss when the stakes are low. It becomes a much harder question when you're allocating significant budgets, making inventory commitments, or planning a quarter based on what your AI is telling you.
The brands that win with AI won't be the ones who adopted it first. They'll be the ones who adopted it right, with tools that were built to understand their unique business environment. That means metrics defined precisely, historical context baked in, and analysis grounded in how ecommerce actually works.
The Context Engine is Triple Whale's answer to that question, built before you ever had to ask it.
Inaccurate AI outputs don't always look off. That's what makes them dangerous.
The numbers are pulled correctly, the response is formatted cleanly, and the confidence in the tone gives you no reason to question them. But somewhere in the logic, a metric was calculated wrong, a relationship between data points was missed, or an operational change wasn't accounted for. And you don’t want to be in the position of catching these mis-steps after the fact.
The gap between tools isn’t the AI model. What separates them is trusted context: a grounded, specific understanding of how your commerce business actually works. That’s what Triple Whale built the Context Engine to provide, and it’s something that can’t be vibe-coded or cloned.
In a world where most platforms are shipping an AI layer, the product difference comes down to how well they comprehend the business behind the data. With data collected from over 60K brands daily, we know it inside and out.
There's a version of AI-powered analytics that's become pretty standard: connect a language model to your data, let it generate responses, call it intelligent. It works well enough when the questions are simple. It falls apart when the questions are nuanced and business growth depends on the outputs.
The reason isn't that the underlying models are bad. It's that intelligence without context produces confident-sounding guesses. And in ecommerce, a confident-sounding guess dressed up as analysis can do real damage. You scale a campaign that was already fatiguing. You pull budget from a channel that was actually working. You forecast inventory on projections that had no business context behind them.
Generic AI tools have access to your numbers. What they're missing is everything that makes those numbers mean something.
The Context Engine is the intelligence trust layer that sits beneath Moby, Triple Whale's AI.
It's a set of interconnected capabilities that together give Moby genuine fluency in how your business operates: how your data is defined, how your metrics relate to each other, what good looks like for brands like yours, what your team has actually done across your ad accounts, and what experienced operators do when faced with the same situation you're in.
Together, they make Moby's outputs trustworthy in a way that general-purpose AI tools simply cannot replicate.
Moby connects directly to your live business data and queries it in real time. No exports, no uploads, no separate data feeds to maintain. When you ask a question, Moby is looking at what's actually happening right now — across all of your primary data sources — ready to query at a moment's notice.
Most operators using generic AI tools don't have this luxury. They're downloading data from their platforms, uploading it to an LLM, and working with something that's already outdated the moment it leaves the source. Some are going further — using browser-based tools to scrape data in real time — but that approach is slow, brittle, and prone to pulling inaccurate numbers. Either way, the data pipeline itself becomes a liability before any analysis even begins.
In an industry like ecommerce that moves fast, you can’t afford that delay. That’s why Moby can also run on a schedule to check any connected dataset as often as every 30 minutes, meaning the decisions you're making are grounded in what's actually happening, not a snapshot from whenever you last ran a download.
This matters even more when you factor in advertising data. Triple Whale goes beyond just connecting to your store data — we have accurate, first-party measurement for your advertising performance across platforms. That's a fundamental advantage over simply feeding platform exports into Claude or ChatGPT. Plus, ad platforms themselves report differently, use different attribution windows, and define metrics inconsistently. So, the data getting uploaded can have a schema mismatch and a generic LLM working from a raw export has no way of knowing that. Moby does.
Underneath all of this is a structured data retrieval system that Triple Whale has spent over three years building and refining. With the latest version of Moby, text-to-SQL accuracy has improved by over 40% - from a 0.61 SQL score to 0.85 driven by a fully agentic retrieval architecture.
That jump came from two things working together. First, a fundamental redesign of the retrieval system, moving from a predefined, multi-step data workflow to an agentic architecture where Moby reasons through each query dynamically: adaptive knowledge base lookups mid-reasoning, parallel query execution, and self-correction logic that catches edge cases before they become bad outputs.
Second, a new generation of frontier models. Moby gives users access to state-of-the-art models from all three leading labs — including GPT 5.4, Claude 4.6 Opus, and Gemini 3.1 Pro — out of the box. The agentic architecture performs well with any model, but the visible leap in accuracy and intelligence came when these two pieces clicked together.
The result is an AI that answers harder questions correctly. The kind of questions that involve multiple data sources, complex time windows, and metrics that need to be calculated rather than simply looked up. And Moby learns from every interaction: the more your team uses it, the sharper it gets.
The accuracy comes from Triple Whale's semantic layer: a data dictionary and ontology that defines every metric, every calculation, and every relationship between data points with precision.
Why is this important? Ecommerce metrics don't exist in isolation. Your new customer acquisition cost connects to your LTV, which connects to your payback period, which connects to how aggressively you should bid on top-of-funnel keywords. A ROAS number means something very different for a brand with high repeat purchase rates than for one that's almost entirely new customer dependent.
Generic AI tools know what ROAS stands for. They don't understand how it should inform decisions given your specific business model and margin structure.
Moby does, because Triple Whale has built a domain knowledge layer that maps how ecommerce metrics relate to each other and what they mean in different business contexts.
You're getting output from something that reasons about ecommerce the way an experienced operator would, not something that pattern-matches against common business content from the web.
One of the more quietly powerful parts of the Context Engine is the commerce-playbook component. We worked with real ecommerce marketing experts to build analysis frameworks and diagnostic workflows that Moby applies automatically across all accounts.
In practice, this means when you ask Moby why your CPA spiked, it doesn't just pull the number and describe the change. It walks through the same diagnostic an experienced media buyer would run: checking spend allocation across channels, looking for creative fatigue signals, comparing performance across audience segments, surfacing anomalies in your bid strategy. You're getting analyst-grade thinking baked into the default behavior.
For operators who are newer to this level of analytical rigor, the playbooks provide a structured starting point. For operators who are already sophisticated, they accelerate analysis significantly. Either way, you're not building from a blank slate.
And the playbook library isn't static. If your team has developed its own way of diagnosing performance or evaluating creative, you can teach it to Moby directly. Just walk Moby through your process (playbook) in a conversation and tell it to remember. From that point forward, Moby applies your playbook the same way it applies the expert-built ones. The result is an AI that gets smarter about how your specific team thinks, on top of everything it already knows about ecommerce.
Every metric exists on a spectrum, and knowing where you land on that spectrum changes how you respond to it.
A 20% conversion rate is either a sign of a healthy check-out engine or a warning sign, depending entirely on what comparable brands in your category look like. Moby has access to industry benchmark data and references it automatically when contextualizing your performance.
So when it surfaces a number, it can also tell you whether that number is strong, average, or worth paying attention to. This shifts the analysis from simply being descriptive to directional.
Here's a common frustration: you're looking at a performance drop from three weeks ago and you have no idea what caused it. You know something changed, but you just can't trace it.
Triple Whale automatically records every campaign, ad set, and ad change across all connected platforms, including changes made directly on Meta or Google outside of Triple Whale. Moby has access to this full activity history and uses it to connect performance shifts to specific actions.
So when your CPA spikes on a Thursday, Moby can surface that someone changed your bid strategy on Wednesday. When revenue dips the week after a creative refresh, Moby can link those two events and help you understand the relationship. Most AI tools can describe what happened to your metrics. The action log gives Moby the ability to explain why, which is really the only version of that answer that's actually useful.
Off-the-shelf forecasting models are trained to find patterns in time-series data. Understanding why ecommerce time-series data looks the way it does is a different challenge entirely.
A DTC brand running a sitewide sale creates a revenue spike that a generic model could treat as an anomaly. A brand launching a new hero product creates customer acquisition patterns that look nothing like their historical baseline. Post-holiday revenue normalization follows curves that are specific to how ecommerce businesses behave, not how businesses at large behave.
Triple Whale's forecasting model is trained on aggregated data from thousands of ecommerce stores. It's seen these patterns play out at scale, across categories, business models, and growth stages.
When Moby produces a projection, it's drawing on that library of real ecommerce behavior, instead of producing a statistical curve that’s fitted to your own historical data in isolation.
At some point, every operator using AI for business decisions will have to answer a simple question: do I actually trust this output? It's easy to dismiss when the stakes are low. It becomes a much harder question when you're allocating significant budgets, making inventory commitments, or planning a quarter based on what your AI is telling you.
The brands that win with AI won't be the ones who adopted it first. They'll be the ones who adopted it right, with tools that were built to understand their unique business environment. That means metrics defined precisely, historical context baked in, and analysis grounded in how ecommerce actually works.
The Context Engine is Triple Whale's answer to that question, built before you ever had to ask it.

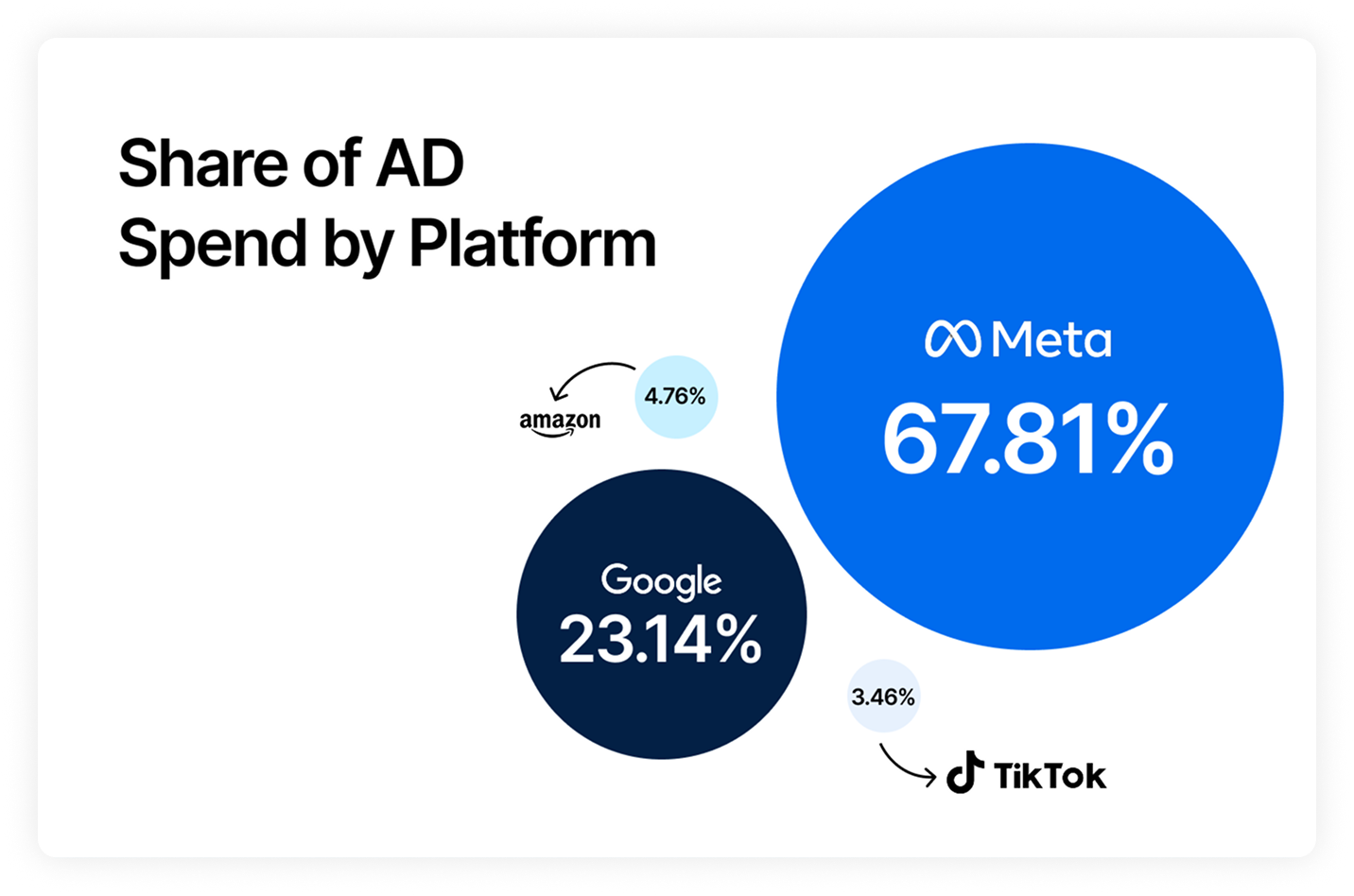
Body Copy: The following benchmarks compare advertising metrics from April 1-17 to the previous period. Considering President Trump first unveiled his tariffs on April 2, the timing corresponds with potential changes in advertising behavior among ecommerce brands (though it isn’t necessarily correlated).




.webp)

.webp)

.png)




.png)
.png)
.png)